ZODB
ZODB 3.8 版本之後,提供 blob 大型檔案支援,透過 plone.app.blob 讓 Plone 模組能夠享用這項功能,原本使用 File 或 Image 型別的模組,可以把資料轉存到檔案系統裡。ZODB3 後來分成 persistent, BTree, ZODB 三個模組。
文章 Zope Secrets 說明 ZODB 核心運作機制。LxBTree 使用 Py_LongLong (a signed type) 做為 key,功能之一是處理 forward index。現有的 ZODB 和 ZEO 實作方式,假定 OID 和 TID 都是 64-bit 數值,通常可用 64-bit 整數來表示。
效能簡介
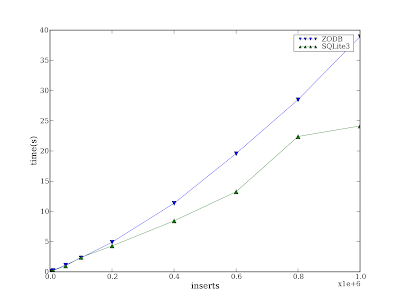
ZODB Benchmarks revisited by Roché Compaan
The truth is that the ZODB is faster than your RDBMS. My previous post about ZODB benchmarks incorrectly confirmed the general opinion people had of the ZODB which is that it is not very fast when you want to insert millions of objects into it. Many developers will tell you, the ZODB is a low-write high-read database. Many more developers will reduce this to a slating "the ZODB is slow".
Fortunately this is not true! I overlooked a basic thing when I compared ZODB performance with Postgres. I only realised that the Postgres table did not have an index on the key field when I started testing lookup speed. After adding the index I neglected to re-run the insertion test on Postgres. I realised this soon after I wrote up my findings and ran the test again. Adding the index causes the insertion on Postgres to drop logarithmically at a higher rate than the ZODB.
For the most part of the test, insertion is faster in the ZODB than in Postgres. Wow, I didn't expect that! I don't know about you but this is a very comforting result for me. There was a bug in my lookup test as well. After fixing this bug the times for lookups were looking a lot better:
| Number of Objects | Average Lookup Time in Seconds |
|---|---|
| 100000 | 0.00000311 |
| 1000000 | 0.00000648 |
| 10000000 | 0.00230820 |
From the above table it is clear that lookups on a BTree with 10 million objects is very fast at around 2 milliseconds. On a Postgres table with 10 million records the average lookup time was 14 milliseconds.
It wasn't my original goal to compare the ZODB with Postgres - I simply used Postgres as a reference point. I do think that the comparison was necessary to "fix" the perception people have of the ZODB. I love the ZODB and were looking really hard for reasons to justify my extensive use of it but benchmarks weren't available. Nevertheless, this is just a starting point. The tests are still very superficial, almost deliberately so since it allows one to compare apples with apples. I think applications like Zope and Plone generally do a lot more with the ZODB than what an RDMBS allows. I mean, of how many systems have you heard that has per-object security and indexed meta data for the majority of the content. I think it would be worthwhile to start quantifying how many objects are modified with common actions in Zope and Plone in a single transaction. This should give us an appreciation of how hard the ZODB is working. Our work is not done.
@vangheezy: 讀的效能很好,但多人同時寫的效能不好,大量資料情況下的索引效能也不好。
@paulweveritt: PostgreSQL JSONB
@JimFulton: Optimizations Featuring Prefetch ZEO Client on Android
想要觀察 Plone 應用 ZODB 的效果,可以檢查 FileStorage 和 BlobStorage 目錄裡的檔案,前者的檔案位置通常是 var/filestorage/data.fs,後者的目錄位置通常是在 var/blobstorage。
想要管理 ZODB 儲存容量,可以執行 pack 並清除不再使用的 blob。
zodbpickle 使用客製化的 pickle
Zope Replication Services (ZRS)
FileStorage
Data.fs 舊版系統會持續容量膨脹
BlobStorage
新增檔案或圖檔後,預設會以 Blob 格式儲存在檔案系統裡,檔案會以原有大小儲存,圖檔還會視情況同步儲存不同尺寸的縮放檔案。
如果 BlobStorage 獨立掛載,利用 experimental.gracefulblobmissing 可以改善空窗時段的讀取問題。
下列是上傳 1.png (725,985 bytes) 的結果:
$ ls -lR var/blobstorage/ var/blobstorage/: total 8 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 drwx------ 2 marr marr 4096 Jul 27 20:13 tmp var/blobstorage/0x00: total 4 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 var/blobstorage/0x00/0x00: total 4 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 var/blobstorage/0x00/0x00/0x00: total 4 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 var/blobstorage/0x00/0x00/0x00/0x00: total 4 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 var/blobstorage/0x00/0x00/0x00/0x00/0x00: total 4 drwx------ 3 marr marr 4096 Jul 27 20:13 0x00 var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00: total 4 drwx------ 5 marr marr 4096 Jul 27 20:13 0x11 var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11: total 12 drwx------ 2 marr marr 4096 Jul 27 20:13 0x55 drwx------ 2 marr marr 4096 Jul 27 20:13 0x6c drwx------ 2 marr marr 4096 Jul 27 20:13 0x81 var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x55: total 0 -r-------- 1 marr marr 0 Jul 27 20:13 0x03a04fdd73235e22.blob var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x6c: total 712 -r-------- 1 marr marr 725985 Jul 27 20:13 0x03a04fdd73235e22.blob var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x81: total 164 -r-------- 1 marr marr 164975 Jul 27 20:13 0x03a04fdd77d56e55.blob var/blobstorage/tmp: total 0
$ tree var/blobstorage . ├── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x11 │ ├── 0x55 │ │ └── 0x03a04fdd73235e22.blob │ ├── 0x6c │ │ └── 0x03a04fdd73235e22.blob │ └── 0x81 │ └── 0x03a04fdd77d56e55.blob └── tmp
933 x 512 是原圖尺寸,400 x 219 是 preview 尺寸。
$ file var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x6c/0x03a04fdd73235e22.blob: PNG image data, 933 x 512, 8-bit/color RGB, non-interlaced var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x81/0x03a04fdd77d56e55.blob: PNG image data, 400 x 219, 8-bit/color RGB, non-interlaced var/blobstorage/0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x55/0x03a04fdd73235e22.blob: empty
在 portal_catalog 裡查詢它的 UID 是 9110c1329a1c46a09a4c99eec2e156aa。
將 1.png 刪除後,會增加一個 200 x 109 的 blob。
$ tree . ├── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x11 │ ├── 0x55 │ │ └── 0x03a04fdd73235e22.blob │ ├── 0x6c │ │ └── 0x03a04fdd73235e22.blob │ ├── 0x81 │ │ └── 0x03a04fdd77d56e55.blob │ └── 0x82 │ └── 0x03a058decaf30daa.blob └── tmp
$ ls -l 0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x82/0x03a058decaf30daa.blob -r-------- 1 marr marr 44952 Jul 29 10:38 $ file 0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x82/0x03a058decaf30daa.blob PNG image data, 200 x 109, 8-bit/color RGB, non-interlaced
執行 pack 後,blob 檔案會被移除,只留下目錄:
$ tree . ├── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x11 └── tmp
重新上傳 1.png 的話:
$ tree . ├── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x00 │ └── 0x11 │ ├── 0x8b │ │ └── 0x03a058ec7afd4ebb.blob │ ├── 0xa3 │ │ └── 0x03a058ec7afd4ebb.blob │ └── 0xb8 │ └── 0x03a058ec7fb658aa.blob └── tmp
$ ls -lR 0x00/0x00/0x00/0x00/0x00/0x00/0x11/ 0x00/0x00/0x00/0x00/0x00/0x00/0x11/: total 12 drwx------ 2 marr marr 4096 Jul 29 10:52 0x8b drwx------ 2 marr marr 4096 Jul 29 10:52 0xa3 drwx------ 2 marr marr 4096 Jul 29 10:52 0xb8 0x00/0x00/0x00/0x00/0x00/0x00/0x11/0x8b: total 0 -r-------- 1 marr marr 0 Jul 29 10:52 0x03a058ec7afd4ebb.blob 0x00/0x00/0x00/0x00/0x00/0x00/0x11/0xa3: total 712 -r-------- 1 marr marr 725985 Jul 29 10:52 0x03a058ec7afd4ebb.blob 0x00/0x00/0x00/0x00/0x00/0x00/0x11/0xb8: total 164 -r-------- 1 marr marr 164975 Jul 29 10:52 0x03a058ec7fb658aa.blob
刪除 File 的情況下,可能不會馬上移除 Blob。
Conflict Error
當一個以上的 request 同時要寫入 ZODB 時,會造成衝突,有些 request 被迫要重試寫入。這類狀況本身問題不大,但代表系統可能需要調整執行效能。
@vangheezy: ZODB Blobs are nice but only nice to replicate them is ZRS. It gets tricky with RelStorage.
vangheem: making a change to the ZODB on a slave, would make the replication get out of sync and it won't replicate anymore.
plone.app.blob.utils.openBlob()
Handling multiple object creations at once from multiple clients and processes
Relstorage: Abstract ZODB's MVCC implementation into a storage adapter lastTransaction
etc/zope.conf
zc.beforestorage: View ZODB Storage Before a Given Time
Blob Directory Layout
在 var/blobstorage 目錄裡,找得到 .layout 檔案,裡面記錄目錄結構的管理方式,例如新版預設使用 bushy 格式。舊版使用 lawn 格式,建議昇級成 bushy 格式。
# ZODB3-3.10.5-py2.6-linux-i686.egg/ZODB/blob.py def getOIDForPath(self, path): """Given a path, return an OID, if the path is a valid path for an OID. The inverse function to `getPathForOID`. Raises ValueError if the path is not valid for an OID. """ path = path[len(self.base_dir):] return self.layout.path_to_oid(path)
"Catalog" is the usual term in ZODB-land (because a catalog contains one or more indexes). These aren't provided by ZODB itself, but there are packages that provide them on top of ZODB. E.g. one of those is repoze.catalog.
BTree 4.4.0 重新啟用 None 當作 Key Products.ExtendedPathIndex 同時被修訂
persistent dependency: ZODB3 包含 persistent 相依關係,但早期版本有相容性問題。
ZODBConvert: 加密 encrypt ZRS cipher.encryptingstorage
沒設定 UTC 系統時間 historical_connections time.time 會造成錯誤
TempStorage: RAM based storage for ZODB DemoStorage: Conflict Resolution and Fix history()
Traversal
response = traverse(root, HTTP_PATH.split('/'), request)
def traverse(context, path, request):
if len(path) == 0:
return context(request)
elif len(path) == 1:
view_method = getattr(context, path[0])
return view_method(request)
else:
sub_context = context[path[0]]
return traverse(sub_context, path[1:], request)
if not container.REQUEST.REMOTE_ADDR.startswith('141.233.'):
return ""
plone_site_search_depth = 3 # depth it will search, from the zope root, for plone sites
def find_honking_files(plone):
"""
Steps:
1. look at Plone content types
2. look in portal skins
"""
pc = plone.portal_catalog
brains = pc.searchResults({'portal_type' : ('Image', 'File', 'News Item') })
brains = list(brains)
#brains.filter(lambda x : "MB" not in x.getObjSize)
#brains.sort(lambda x, y : x.getObjSize > y.getObjSize)
for b in brains:
size = b.getObjSize
if "MB" in size or "GB" in size:
url = b.getURL()
print "%s %s
" % (size, url, url)
ps = plone.portal_skins
def find_big_ones(current):
found = []
for x in current.objectIds():
obj = current[x]
if hasattr(obj, 'getContentType') and str(obj.getContentType()).strip().startswith('image'):
size = (float(obj.get_size())/1024.0)/1024.0
if size > 1.0:
print "%s MB : %s
" % (str(size)[:4], obj.id())
if hasattr(obj, 'objectIds'):
print find_big_ones(obj)
return printed
print find_big_ones(ps)
return printed
def get_plone_sites():
def find_it(current_context, depth):
if depth == 0:
return []
else:
sites = []
for obj in current_context.objectIds():
site = current_context[obj]
if hasattr(site, 'portal_type') and site.portal_type == 'Plone Site':
sites.append(site)
elif hasattr(site, 'objectIds'):
sites.extend(find_it(site, depth - 1))
return sites
return find_it(context, plone_site_search_depth)
sites = get_plone_sites()
for site in sites:
print "Plone Site: %s
" % site.title
print find_honking_files(site)
return printed
OSError: [Errno 12] Cannot allocate memory /home/marr/Plone/buildout-cache/eggs/ZODB3-3.10.5-py2.7-linux-x86_64.egg/ZODB/Connection.py:660: UserWarning: The <type 'BTrees.IOBTree.IOBucket'> object you're saving is large. (24951980 bytes.) Perhaps you're storing media which should be stored in blobs. Perhaps you're using a non-scalable data structure, such as a PersistentMapping or PersistentList. Perhaps you're storing data in objects that aren't persistent at all. In cases like that, the data is stored in the record of the containing persistent object. In any case, storing records this big is probably a bad idea. If you insist and want to get rid of this warning, use the large_record_size option of the ZODB.DB constructor (or the large-record-size option in a configuration file) to specify a larger size. warnings.warn(large_object_message % (obj.__class__, len(p))) Killed
collective.firehose: for heavy-write scenarios