Performance
TAL Path Expression 會影響效能 <tal:if tal:condition="image"> 可考慮 <tal:if tal:condition="nocall:image"> 或 <tal:if tal:condition="python:image">
yesterday, more than 10.000 concurrent users; 460.000 sessions; 1.150.000 page views #Plone powered! https://t.co/24Rgs1WMJy
— hvelarde (@hvelarde) March 17, 2016
已知超過 20K 項目的網站,執行 reindex 動作時,常會遇到耗用大量資源和時間。以 /a/b/c 目錄結構為例,執行 a 的 reindex 會引發 b 和 c 重複執行 reindex 動作,也可能遇到 Conflict 狀況。改善方式是分批執行。原因不是 ZODB 效能不佳,而是多數 Plone 應用程式依賴 portal_catalog 執行索引,成為單點瓶頸,無法非同步分散索引工作。
large number of HTTP requests with asyncio, aiohttp, pypeln
Linux Analysis Products.LongRequestLogger Locust: load testing tool
Renaming Moving a Folder with Lots of Contents: Such operations are handled basically on the Zope level (CopyManager) and there is no way to get hold of any kind of "progress" information without extending the CopyManager API of Zope. And for a move operation the complete old contents will be unindexed and the new content will be indexed as well. By default there is no way to determine how expensive such an operation might be. From the Plone level you might introspect the path index and get the number of objects in the related subtree - however not only the number objects matter but also there size and type.
When Performance Matters by Marc-André Lemburg, eGenix howto intro
Many Options: netsight.async 簡易處理 504 Gateway timeout - multiple object creation timeout example plone.app.async: asyncworker not un/re-reregistering in queue
High Performance High Availability
HA Tips plone.synchronize plone.subrequest Guido Stevens PythonBrasil 2013
use RelStorage with PostgreSQL or Oracle not MySQL
use Solr for catalog where possible (for example: collective.workspace catalog query of 25,000 items is problematic)
StackOverflow Case Plone3 + Zeo collective.recipe.filestorage: Support Multi ZEO Servers
Asyncio-based ZEO Server and Client uvloop in the Single-Threaded Server eea.sparql: Move cached_result to Blob Field
Server Configuration Tuning
常見的 Linux 掛點原因: 預設 1024 File Descriptor 另外 ip_conntrack 是追蹤連線的記錄表,超過限量的封包會被丟掉。
Elizabeth Leddy: Unloading Plone munin: a tool records all activities on the system over time
Products.ZCatalog: Caching Support for Unindex
Products.ZNagios: for Nagios and munin to tap into the Zope2 server and retrieve status and performance data Database Scalability
ZODB Benchmarks: year 2008
Transaction SavePoints: plone.app.linkintegrity
Cache
collective.warmup ZestSoftware Guidelines
folderish content types performance efficiency
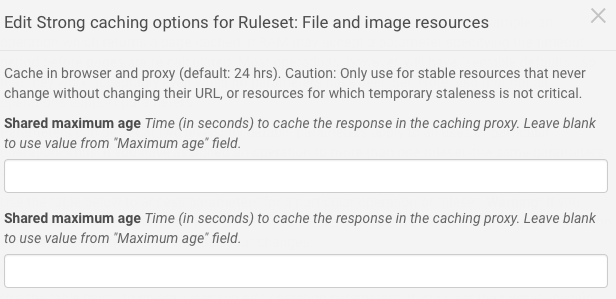
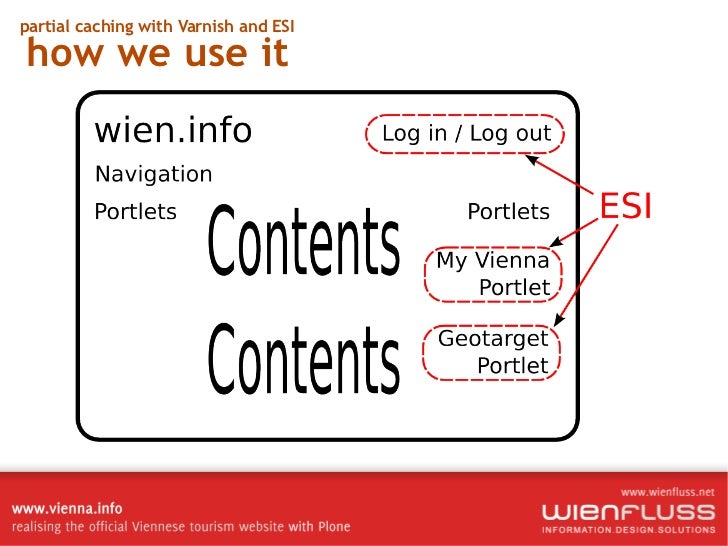
Cache Headers for Varnish Varnish + ESI Updating Attached Image of NewsItem Does Not Purge Scaled Image from Varnish but Only the NewsItem View
Caching View Viewlet Methods View Memorize and Template Render: sc.social.like
Build Cache Mechanism Inside Function And Not Rely On Decorator
pickle size and memory size are correlated
Threads-per-instance instances-per-core
Memoize: Decorator
from plone.memoize import instance
class MyClass(object):
@instance.memoize
def some_function(self, arg1, arg2):
...
from plone.memoize import view
class MyView(BrowserView):
@view.memoize
def some_function(self, arg1, arg2):
...
from Products.Five import BrowserView
from plone.memoize import ram
def _render_cachekey(method, self, brain):
return (brain.getPath(), brain.modified)
class View(BrowserView):
@ram.cache(_render_cachekey)
def render(self, brain):
obj = brain.getObject()
view = obj.restrictedTraverse('@@obj-view')
return view.render()
from time import time
...
class View(BrowserView):
@ram.cache(lambda *args: time() // (60 * 60))
...
Memcache
from zope.interface import directlyProvides
import zope.thread
from plone.memoize.interfaces import ICacheChooser
from plone.memoize.ram import MemcacheAdapter
import os
import memcache
thread_local = zope.thread.local()
def choose_cache(fun_name):
global servers
client=getattr(thread_local, "client", None)
if client is None:
servers=os.environ.get(
"MEMCACHE_SERVER", "127.0.0.1:11211").split(",")
client=thread_local.client=memcache.Client(servers, debug=0)
return MemcacheAdapter(client)
directlyProvides(choose_cache, ICacheChooser)
# override.zcml
<configure
xmlns="http://namespaces.zope.org/zope">
<utility
component=".caching.choose_cache"
provides="plone.memoize.interfaces.ICacheChooser" />
</configure>
與Firch大聊到Memcache實做 Lock的問題 作法是這樣:
function Lock($Key,$LockExpire){
while(!$Memcache->add($Key,false,$LockExpire)
usleep(rand(1,5000));
}
function ReleaseLock($Key){
$Memcache->delete($Key);
}
Firch大也提到了他在高concurrency 的情況下就是會發生同時取得Lock的情況。 剛剛去翻了一下Memcache的Doc找到了這個 http://code.google.com/p/memcached/wiki/FAQ#Is_memcached_atomic? 官方也提到了Memcache存取同一個resorce時,所有的command都是atomic。 照官方的規範,上面的方式是不應該發生同時取得Lock的情況,如果有那就是Bug。
plone.memoize Prevent RAM Caching View/Viewlet Methods Return Values by self.request
plone.memoize.instance: ZEO Clients + redis
Remove Users from a Large Site: deleteMembers() function is calling recursively deleteLocalRoles() and using transaction.savepoint() in the loop or response.write() to keep the proxy from time out. Once a site reaches that size, you should probably be using GUIDs for userids, that way you can remove a user without needing to remove their local roles.
more efficient:
def deleteLocalRoles(self, obj, member_ids, reindex=1, recursive=0, REQUEST=None):
""" Delete local roles of specified members.
"""
if _checkPermission(ChangeLocalRoles, obj):
for member_id in member_ids:
if obj.get_local_roles_for_userid(userid=member_id):
obj.manage_delLocalRoles(userids=member_ids)
break
catalog = getToolByName(obj, 'portal_catalog')
if recursive and hasattr( aq_base(obj), 'contentValues' ):
for subobj in obj.contentValues():
self.deleteLocalRoles(subobj, member_ids, reindex, 1)
if reindex and hasattr(aq_base(subobj), 'reindexObjectSecurity'):
s = getattr(subobj, '_p_changed', 0)
path = '/'.join(subobj.getPhysicalPath())
catalog.reindexObject(subobj, idxs=subobj._cmf_security_indexes,
update_metadata=0, uid=path)
if not s: subobj._p_deactivate()
HTTP/2 supports "server push" which obsoletes bundling of resources.
Cache Purge: collective.workspace
Plone time-out 因為python沒有像javascript那樣非同步滿天飛還有各種支援非同步的套件,所以基本上asyncio是不太適合做這種任務分配的工作,可能要交給多線程或celery之類的工具處理 python asyncio應該大多用在網頁伺服器和GUI事件處理上